Einleitung
Bei der Durchführung eines Rich-Client Penetrationstests stellen wir immer wieder fest, dass sicherheitsrelevante Funktionen im Client verankert sind. Ein sehr häufiges Beispiel ist, dass die Berechtigungsprüfung dahingehend implementiert wird, dass gewisse Menüeinträge bzw. Buttons nur unter bestimmten Voraussetzungen angezeigt werden. Was aus Sicht der Benutzerfreundlichkeit durchaus Sinn macht, ist in Bezug auf die Sicherheit leider nicht empfehlenswert.
Im heutigen Blog-Artikel möchte ich aufzeigen, wie einfach der Ablauf von .NET-Applikationen manipuliert werden kann. Damit soll dargestellt werden, warum clientseitige Schutzmaßnahmen nicht wirksam sein können.
Die Common Intermediate Language (CIL)
.NET-Applikationen, egal ob diese mit C# oder mit Visual Basic entwickelt wurden, werden nicht direkt in Maschinencode übersetzt. Ähnlich wie bei Java kommt eine Zwischensprache zum Einsatz, die den Byte-Code während der Laufzeit interpretiert. Im Fall von .NET ist dies die Common Intermediate Language (CIL, früher Microsoft Intermediate Language). Im Prinzip können alle .NET-Applikationen auch in einer assemblerähnlichen Repräsentation der CIL entwickelt werden, auch wenn das eher nicht zu empfehlen ist. 😉
Der Vorteil der CIL ist, dass dieser Code – ähnlich dem Java-Byte-Code – portabel ist. Wenn auf einer Plattform eine entsprechende Laufzeitumgebung installiert ist, kann der Code ausgeführt werden. Plattform ist hierbei nicht nur auf Betriebssystemebene zu verstehen, sondern auch auf Prozessorebene. Die bekanntesten Vertreter sind in der Windows-Welt die .NET-Laufzeitumgebung von Microsoft. Unter Linux ist Mono verfügbar, das inzwischen einen Großteil der Funktionalität von .NET abbilden kann.
Zugriff auf den Byte-Code
Ein Byte-Code ist in vielen Fällen bedeutend aussagekräftiger als normaler Maschinen-Code. Zum einen ist die Struktur des Programms noch erhalten. Somit ist klar ersichtlich, welche Klassen definiert sind und wie Methoden oder Variablen benannt wurden. Zum anderen ist der grundsätzliche Programmablauf klar, wie beispielsweise der Einsatz von Schleifen oder Switches. Im klassischen x86-Assemblercode sind manche dieser Konstrukte nicht so offensichtlich, was die Analyse von Byte-Code meist erleichtert. Für unseren Rich-Client Penetrationstest ist das natürlich optimal. 😉
Des Weiteren gibt es sehr viele Tools, die die Möglichkeit bieten, vorhandenen CIL-Code zu dekompilieren. Dies funktioniert auch in der Praxis sehr gut. Einer der ersten .NET-Decompiler war der .NET-Reflector, der inzwischen von der Firma Red Gate Software kommerziell vertrieben wird.
Inzwischen gibt es aber auch mehrere hervorragende kostenlose Decompiler. Ein einfach zugänglicher und auf die Kernfunktionen reduzierter Decompiler ist ILSpy [1]. Vergleicht man den originalen Code mit der dekompilierten Version, ist deutlich zu erkennen, dass diese nahezu identisch sind:
using System;
public class SuperSafe
{
static private bool CheckDomain()
{
/*
* Check if current user is part of the securai domain
* return false, if this is not the case.
*/
String currentDomain = System.Environment.UserDomainName;
if (currentDomain.ToLower() == "securai" )
return true;
else
return false;
}
static public void Main ()
{
/*
* Only reveal our secret, if the user is a real securai.
*/
if (SuperSafe.CheckDomain())
Console.WriteLine("You are trustworthy! Here is our secret: ...");
else
Console.WriteLine("You shall not pass!");
}
}
Wird dieser Code kompiliert und mit ILSpy angezeigt, erhält man folgendes Ergebnis:
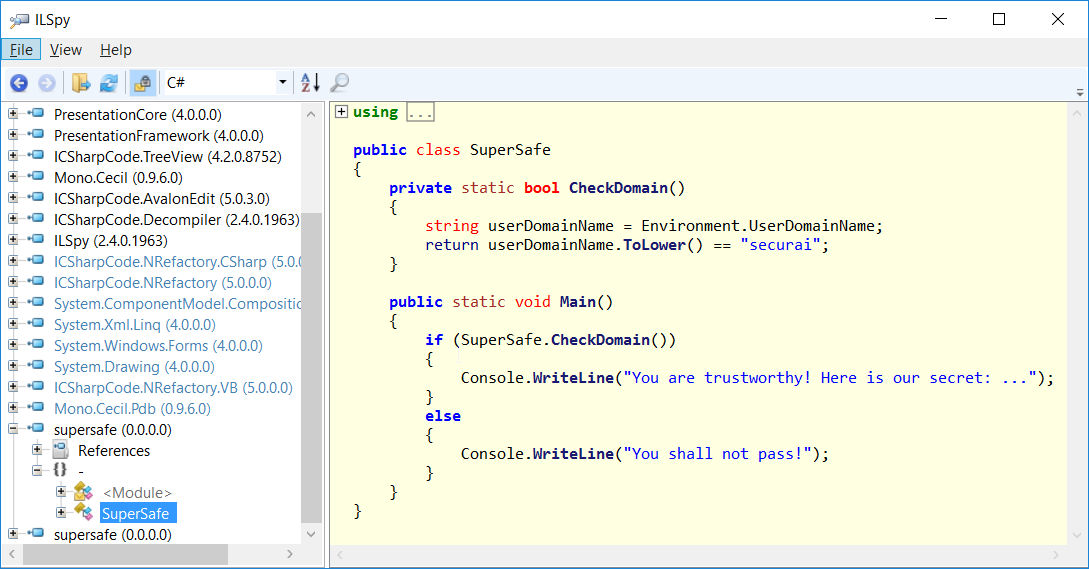
Sehr deutlich zu sehen ist, dass abgesehen von den Kommentaren und einer Optimierung der Anzeige des Codes in der Funktion CheckDomain() der dekompilierte Quelltext identisch mit dem Originalen ist. Besonders praktisch ist hier auch die Funktion „Analyze“, die gerade bei komplexeren Applikationen die Arbeit erheblich erleichtert. So wird angezeigt, wo eine Klasse instanziiert oder benutzt wird.
Analyse des Programms
Schauen wir uns das Beispielprogramm einmal genauer an. Um die „Vertrauenswürdigkeit“ des Benutzers zu ermitteln, wird die Funktion „CheckDomain()“ aufgerufen. Diese verwendet die Umgebungsvariable UserDomainName, um zu ermitteln, in welcher Domäne der aktuelle Benutzer ist. Ist der Benutzer Teil der Domäne „securai“, wird der Zugriff erlaubt.
Nun gibt es mehrere Methoden, um das Programm dazu zu bewegen, das Geheimnis zu offenbaren.
Der allereinfachste Fall – und darauf weise ich nur der Vollständigkeit halber hin – ist es, sich die Dokumentation der UserDomainName-Eigenschaft anzusehen [2]. Dort ist unter den Hinweisen zu finden, dass falls ein Computer nicht Teil einer Domäne ist, der Computername zurückgegeben wird. Kurz: Wird ein Windows mit dem Computernamen „securai“ installiert, ist diese Bedingung wahr und der Zugriff auf das Geheimnis ist möglich. Ich möchte dies an dieser Stelle dennoch erwähnen, da ich schon öfter Programme analysiert habe, die sich auf den Inhalt von bestimmten Umgebungsvariablen verlassen haben – das ist immer eine schlechte Idee!
Die nächste Möglichkeit besteht schlicht darin, die Bedingung umzudrehen. Die Idee ist, dass immer dann „true“ zurückgegeben wird, wenn die Domäne nicht „securai“ ist.
Disassemblierung
Der aufwändige Weg soll gleich am Anfang beschrieben werden und dient hauptsächlich dem Verständnis.
Manchmal schlägt aufgrund von Code-Obfuscation die Dekompilierung fehl. Die meisten Decompiler zeigen dann schlicht den CIL-Code an. In unserem obigen Beispiel sieht dieser für die Funktion „CheckDomain()“ folgendermaßen aus:
.method private hidebysig static
bool CheckDomain () cil managed
{
// Method begins at RVA 0x2058
// Code size 31 (0x1f)
.maxstack 2
.locals init (
[0] string
)
IL_0000: call string [mscorlib]System.Environment::get_UserDomainName()
IL_0005: stloc.0
IL_0006: ldloc.0
IL_0007: callvirt instance string [mscorlib]System.String::ToLower()
IL_000c: ldstr "securai"
IL_0011: call bool [mscorlib]System.String::op_Equality(string, string)
IL_0016: brfalse IL_001d
IL_001b: ldc.i4.1
IL_001c: ret
IL_001d: ldc.i4.0
IL_001e: ret
} // end of method SuperSafe::CheckDomain
Der erste Aufruf lädt den Domainnamen in die lokale Variable. Anschließend wird der Wert auf dem Stack abgelegt und darauf gleich wieder geladen. Der nächste Aufruf (bei IL_0007) führt die ToLower() Funktion aus. Danach wird der String „securai“ auf den Stack gepackt und anschließend die Gleichheit geprüft (op_Equality an Adresse IL_0011).
Der nächste Aufruf ist der spannende, da dies unser „if“ darstellt. Wenn der Rückgabewert der Gleichheitsprüfung „false“ ist, wird an Adresse IL_001d gesprungen, der Wert 0 auf den Stack gelegt und danach zur aufrufenden Funktion zurückgekehrt. Unser Ziel ist es, dass der Wert 1 für „true“ auf dem Stack liegt, bevor die Funktion beendet wird.
Also muss „nur“ der IL-Opcode für brfalse (Branch if false, also springe, wenn falsch) in brtrue geändert werden.
Die Masochisten unter uns können jetzt anhand der Relative Virtual Address (RVA) und der Adresse berechnen, an welcher Position der Aufruf in der Datei liegt und das Byte „0x39“ in „0x3A“ ändern. Der Hexwert „0x39“ entspricht der binären Repräsentation des brfalse Aufrufs, „0x3A“ dem von brtrue.
Wer mehr über die Bedeutung der Opcodes und den zugehörigen hexadezimalen Werten erfahren will, kann dies in der Spezifikation der CIL nachlesen [3] oder kann sich durch die Zusammenfassung auf Wikipedia arbeiten [4].
Disassemblierung des Programms
Einfacher ist es jedoch das Programm zu disassemblieren, den IL-Code zu ändern und anschließend neu zu kompilieren.
Microsoft liefert hierfür das Programm „ildasm“ zusammen mit dem Visual-Studio aus, unter Mono kommt „monodis“ zum Einsatz.
Für unser Beispiel soll Mono verwendet werden, weswegen der folgende Aufruf die disassemblierte Datei erstellt:
$ monodis --output=supersafe.il supersafe.exe
Der Inhalt ist nun in der Datei supersafe.il und wartet darauf, geändert zu werden:
IL_0011: call bool [mscorlib]System.String::op_Equality(string, string) IL_0016: brtrue IL_001d IL_001b: ldc.i4.1
Anschließend kann der Code mit „ilasm“ (sowohl Microsoft, als auch Mono) wieder neu kompiliert werden:
$ ilasm supersafe.il /exe /output:supersafe_fixed.exe Assembling 'supersafe.il' , no listing file, to exe --> 'supersafe_fixed.exe' Operation completed successfully
Anschließend klappt die Ausführung wunderbar:
$ mono supersafe_fixed.exe You are trustworthy! Here is our secret: ...
Disassembler auf Steroiden: dnSpy
Glücklicherweise leben wir im Jahr 2017, wo so viel Handarbeit gar nicht mehr nötig ist. Inzwischen gibt es mehrere Werkzeuge, die ein direktes Dekompilieren, Bearbeiten und Neukompilieren erlauben. Eines dieser Werkzeuge ist das kostenfreie, unter der GPLv3 veröffentlichte, dnSpy, welches im Folgenden vorgestellt werden soll.
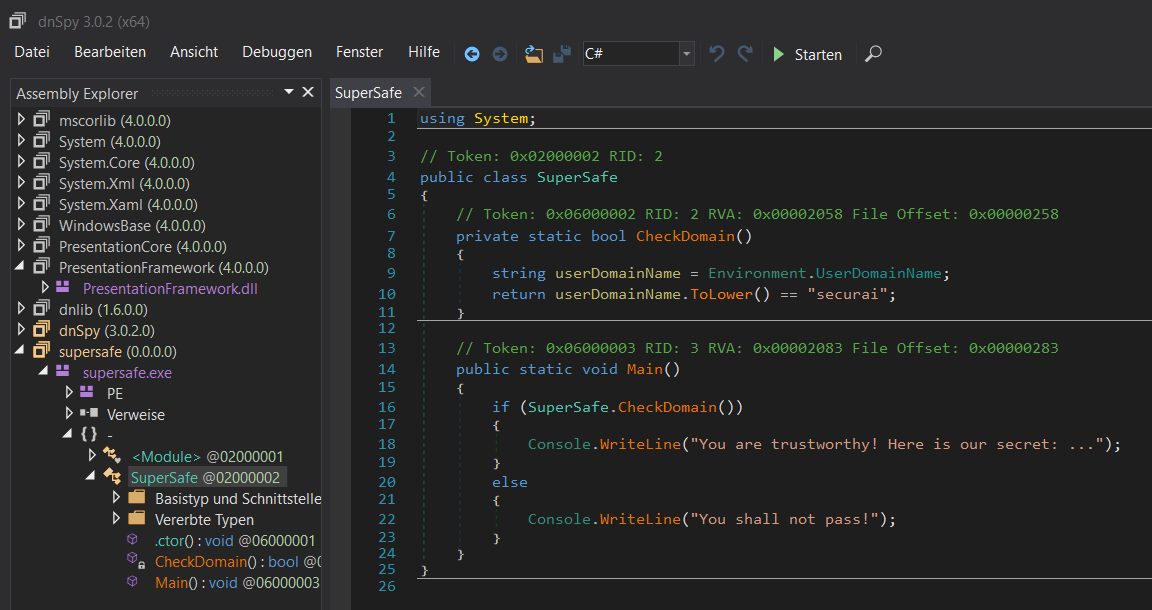
Die Oberfläche ist sehr intuitiv, wenn man den Einsatz gängiger Entwicklungsumgebungen gewohnt ist. Das Besondere an dnSpy ist jedoch, dass der disassemblierte Quelltext direkt bearbeitet werden kann.
Ein Rechtsklick in die entsprechende Methode und dann das Aufrufen von „Edit Method“ erlaubt das direkte Bearbeiten. Da wir uns jetzt nicht mehr mit dem IL-Code „herumschlagen“ müssen, können wir einfach immer „true“ zurückgeben:
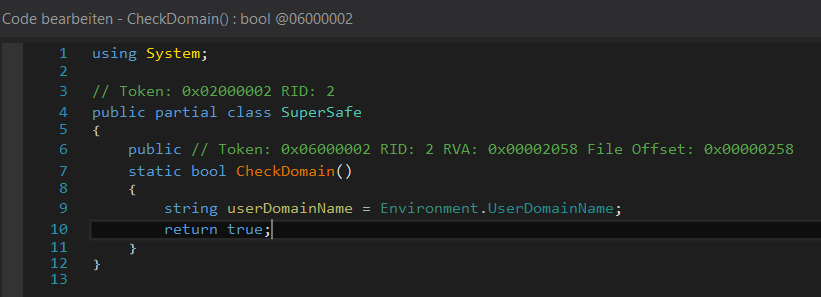
Ein Klick auf „Compile“ bzw. „Kompilieren“ erzeugt dann das entsprechende Codefragment. Die ausführbare Datei kann anschließend unter „Datei“ und „Modul speichern“ erzeugt werden.
Ein weiteres, sehr praktisches Feature ist die Möglichkeit, das Programm direkt zu debuggen. Die Oberfläche bietet hierzu den Button „Starten“, der prominent in der Werkzeugleiste zu finden ist. Bequemerweise wird automatisch ein Breakpoint bei der Main-Routine gesetzt.
Der Debugger von dnSpy ist so mächtig, dass Variablen zur Laufzeit geändert werden können. Dies kann dahingehend genutzt werden, dass einfach der Inhalt der Variable userDomainName zur Laufzeit auf den entsprechenden Wert gesetzt wird:
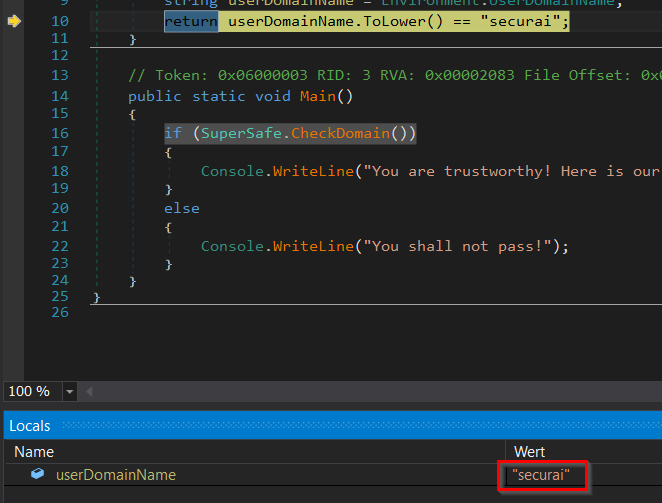
Wichtig ist hierbei zu wissen, dass dafür keine administrativen Rechte benötigt werden. Sobald ein Benutzer dnSpy starten kann, ist es ihm möglich, den Programmablauf beliebig zu manipulieren.
Bei einer Überprüfung, die ich in den letzten Monaten durchgeführt habe, war dies tatsächlich so ein Problem. Der Hersteller hatte das Produkt so angepasst, dass eine Authentifizierung über das Active Directory ermöglicht werden sollte. Der Kunde verfügte über eine Domain, weswegen das entwickelnde Unternehmen leider davon ausging, dass alle Computer darüber verwaltet werden.
Für die „AD-Authentifizierung“ wurde also schlicht und ergreifend die Variable Environment.UserName des Clients verwendet und der Wert an den Server übertragen. Wie leicht das zu manipulieren war, kann sich der Leser nach den vorherigen Ausführungen sicher vorstellen. Das war natürlich schade, da trotz einer Drei-Schicht-Architektur und eines funktionierenden Berechtigungskonzepts die komplette Authentifizierung umgangen werden konnte.
Und die Moral von der Geschicht‘?
Ganz klar: Vertrau dem Client nicht!
Der zentrale Punkt ist folgender: Es macht durchaus Sinn, einem Benutzer clientseitig Funktionen nicht anzuzeigen, auf die er keinen Zugriff hat. Die Benutzerfreundlichkeit wird dadurch massiv erhöht, da weniger Optionen zur Verfügung stehen und nicht bei jedem Aufruf ein „Zugriff verweigert“ zurückgegeben wird.
Dennoch ist der einzige Ort, an dem sicherheitsrelevante Prüfungen durchgeführt werden dürfen, der Applikationsserver. Im Rahmen des Artikels sollte inzwischen klargeworden sein, dass Daten, die vom Client kontrolliert werden, nicht vertrauenswürdig sind und manipuliert sein könnten.
Dies kann in nahezu allen Fällen nur durch eine Drei-Schicht-Architektur Ihrer Software umgesetzt werden, also der Schicht eines Clients, der Einsatz eines Applikationsservers und dahinterliegend die Datenbank. Wichtig ist noch zu erwähnen, dass der Applikationsserver allein auf die Datenbank zugreift. Greift der Client direkt auf die Datenbank zu, ist es fast unmöglich, ein vernünftiges Berechtigungskonzept zu implementieren.




